LeakyReLU is a popular activation function that is often used in deep learning models, particularly in convolutional neural networks (CNNs) and generative adversarial networks (GANs).
In CNNs, the LeakyReLU activation function can be used in the convolutional layers to learn features from the input data. It can be particularly useful in situations where the input data may have negative values, as the standard ReLU function would produce a gradient of 0 for these inputs, which can hinder the model's ability to learn.
In GANs, the LeakyReLU activation function is often used in both the generator and discriminator models. It can help the models learn to generate and classify realistic images more effectively.
LeakyReLU is not the only activation function that can be used in these types of models. Other popular activation functions include ReLU, sigmoid, and tanh. The choice of activation function can depend on the characteristics of the data and the specific goals of the model. Experimenting with different activation functions can sometimes lead to better model performance.
The LeakyReLU (Rectified Linear Unit) activation function is defined as f(x) = max(alpha * x, x), where alpha is a small positive value.
Here is an example plot of the LeakyReLU activation function in Python. This will generate a plot of the LeakyReLU function for input values ranging from -2 to 2, with a default alpha value of 0.01. The resulting plot should look like this:
import matplotlib.pyplot as plt
import numpy as np
def leaky_relu(x, alpha=0.01):
return np.maximum(alpha * x, x)
x = np.linspace(-2, 2, 100)
y = leaky_relu(x)
plt.plot(x, y)
plt.title('Leaky ReLU Activation Function')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.show()
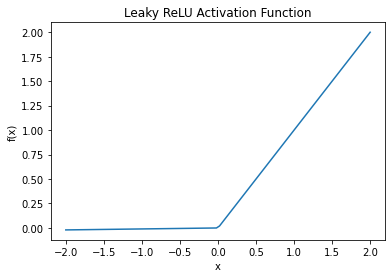
As you can see, the LeakyReLU function is similar to the standard ReLU function, but with a small slope (alpha) for negative input values. This allows the function to have a non-zero gradient for negative inputs, which can help alleviate the "dying ReLU" problem and improve the model's ability to learn.
Related Notebooks
- Activation Functions In Python
- Python Is Integer
- Activation Functions In Artificial Neural Networks Part 2 Binary Classification
- cannot access local variable a where it is not associated with a value but the value is defined
- Return Multiple Values From a Function in Python
- Best Approach To Map Enums to Functions in Python
- Pandas group by multiple custom aggregate function on multiple columns